

今回はPythonを使って「ウェブスクレイピング」をするためにまずHTMLを知る!の回です。
プログラミングの勉強をしたい!と思い、Pythonを学ぶことを決めたものの(→プログラミング言語を選ぶまでの経緯)、まだ何をするかまでは決めていませんでした。
今回は、「Webスクレイピングとは何?」「何ができる?」ということと、私のHTML挑戦記録について綴っています。
まずは目標を決める
プログラミング言語をPythonにすると決めたので、Pythonで何か簡単なものだけでもできるようになろうと書店へ行きました。
そこで見つけたのが「文系でもはじめてでも稼げる!プログラミング副業入門」です。

この本で主に紹介されているのが、「Webスクレイピング」です。
副業入門と書いてはいますが、この内容をすべて学んだだけでは副業で稼ぐのは難しそうです。ここで学べるのは、副業するための基礎のみ!
なぜこの本を選んだかというと、ずらーーーっと並ぶ本たちの中で、この本が一番基礎の基礎、簡単なところから優しい言葉で解説してくれていたからです!
文字がギッシリ詰まっていなかったことも選んだ理由です。
Webスクレイピングが何なのか?は全然理解してませんでしたが(むしろ初耳)、とにかく何かできるようになりたかったのでこの本を手に取りました。
どんなときも見切り発車なわたしです。笑
「ウェブスクレイピング」でできること
Webスクレイピングって私は初めて聞く言葉でした。
Webスクレイピングとは、インターネットという大海原の中から、必要な情報だけを自動で収集することができるプログラムのことです。
自動で入手できる情報の例をざっと並べてみました。
- 各社の商品の変動する価格
- 毎日の株価
- 検索順位
- フリマサイトの最安値
- 画像
- 商品レビュー
- ニュース記事
こういった情報を的確に時間をかけず手に入れられる方法、それがWebスクレイピングです。
Webスクレイピングによって得られるメリットは、「業務の効率化」「ルーティンワークの自動化」です。
例えば、毎日A社、B社、C社…と複数社の同スペック商品価格を確認しているマーケターがいるとします。
このマーケターがWebスクレイピングを利用すれば、作業が自動化できるので手間暇かけすぎずに情報収集ができます。
情報を集める時間を削減した分、統計をとってマーケティング分析や提案書の作成などほかの作業に使えるなどができそうですよね。
もちろん、ウェブスクレイピング以外にもアプリ開発などいろんなことがPythonでできますよ!
Webページの構造を知る
ウェブスクレイピング(情報の自動抽出)をするためには、Webページの構造を知る必要があるということで、まずHTMLとCSSの勉強からはじまります。
「え、Pythonじゃないの?」と思うのですが、遠回りに見えることが実は近道。
Pythonから学んでもWebスクレイピングをやるには結局HTMLを知ることが必須らしく、それなら先にザックリとした枠組みだけでも知っておこう!
そうすると後の学習がスムーズになるよ!ということらしいです。
WebサイトのほぼすべてがHTMLとCSSで作られています。
HTMLは骨格(情報のメイン)、CSSは装飾(文字の大きさや色指定)です。HTMLにプラスでCSSも知ることで、より的確に求める情報をインターネット上から入手することができます。
本書を使う利点は、Webとは何か?HTMLとは何か?の説明のあとに、いくつかの実技コーナーが設けられていることです。
実際に自分の目で見て動かし、「完成させる」ことができるのが良いところです。
必要なデータをダウンロードして使います
ということで、Web構造を知るためにHTMLを実際に触ってみましたよ~
めっちゃ簡単なウェブページを作ってみた!
まずはHTMLを知るために実際にコードを書いてWebページを作ってみる!というところをやってみました!
Google ChromeなどのブラウザにWebページを表示させるには、テキストエディタ(メモ帳)を使います。
ちなみに、わたしはWindowsを使ってるのでこんな見ためです↓
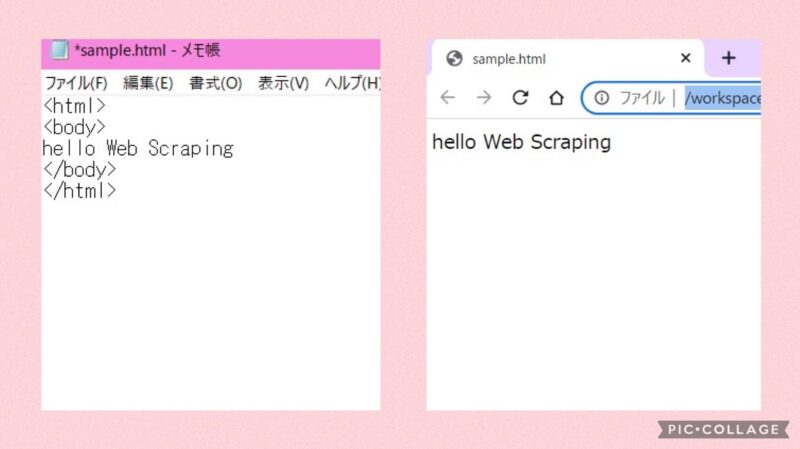
画像の左画面に書かれている < >がタグと呼ばれるものです。
そして、情報の種類を < > で包んであげます。
タグには始まりのタグ < >と終わりのタグ </ > の2種類があるので、この2つのタグの間に表示させたい情報をサンドイッチ!
このサンドイッチした塊を、要素といいます。
上の場合だと、画面に hello Web Scraping と表示させたいので、その言葉を <body> と</body>の間にサンドしています!
わたしの説明だと分かりにくいと思いますが、本を読めばこのあたりのことはもっともっと詳しく書いてます!
こんな風に < > を使ってコードを書いていくんですね。
たった1文字を画面に表示させるために、5行も使いました。。。
画面に表示させるって、紙に絵を描くのとはわけが違いますね。
慣れないので、これだけで「ふぅ〜」って感じ
長らく事務職をしていると、こういう文字入力するときに「コピペしたい」という気持ちに駆られちゃいます。。
でも、今は学ぶために手を動かして1文字ずつ入力あるのみっ!
画像&リンク付きウェブページを作ってみた!
簡単な文字表示はクリアできたので、次に画像とリンク付けをしてみました!
目指す完成イメージはこちら↓

表示させる文章や画像は全て指定されています。(画像も本についてるURLから全部ダウンロードできます!)
ということで、本の指示に従いつつ、入力したものがこちら!
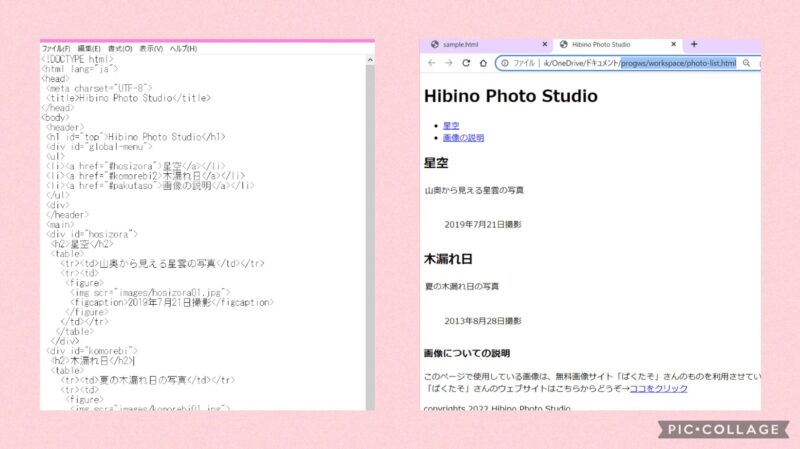
なんと、画像が全く表示されていない!
えええ!なんで?? 3つとも表示されてない。。
しかも、よく見るとリンクも1つ消えています。
本に戻り、「ちゃんと表示されなかったら」のところを読みます。
\落ち着いて、間違っている箇所を探す/
と書いてました。うん、ですよね~。それしかないよね。。
ということで、一言一句間違いがないか探したところ、4箇所の間違いを探しだしました。
- =”#komorebi”> の最後の「”」が抜けていた
- <img src= 「src」ではなく「scr」が正しい(x3カ所)

こんな風に、間違いを見つけてきちんとしたものに修正していきます。(scr と scr の違いを見つけるの、なかなか難しかったです。。)
そして、再度ブラウザで開くと、きちんと表示されていました!
リンクも飛べます!やったー!
一応、ダウンロードした完成イメージのサンプルと見比べてみます。
と、ここでまた問題が発生。
画像サイズが違う!!(本買う人は要注意箇所)
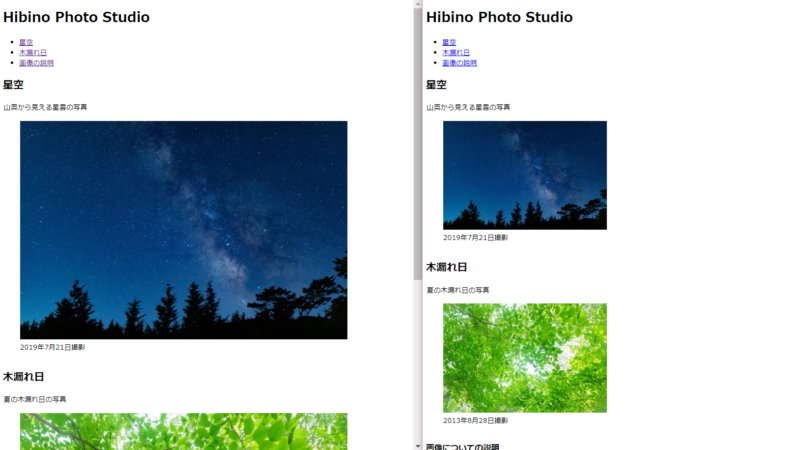
横に並べて見比べると、画像の大きさが全然違う!!
表示倍率は同じ。コードを見返しても、何もおかしいところはない。
それに、コードには画像サイズの指定をしてないからここが影響されることはそもそも無いはず。
ということで、画像データのサイズを見てみると…
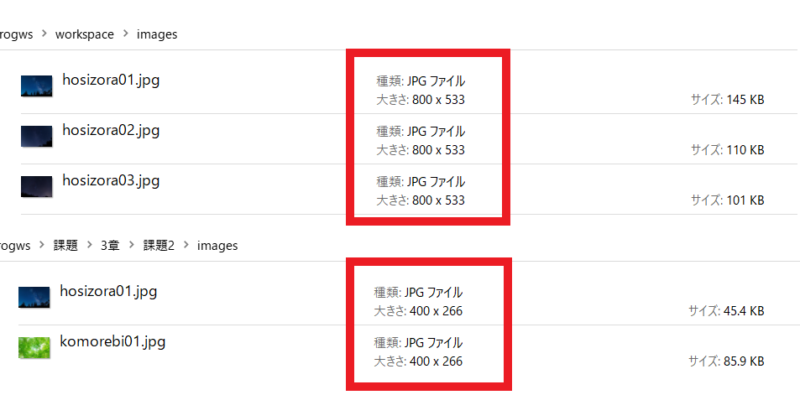
画像のサイズ自体が全然違う!
読者が使う用のフォルダに入っている画像サイズと、完成見本のフォルダに入っている画像サイズが倍違いました。
これ、自分が間違っちゃったんじゃないかと結構焦るやん…!!
でもコードに問題があったわけではないので、HTMLはこれで良しですね。
さいごに
以上、今回はHTMLを学ぶの回でした。
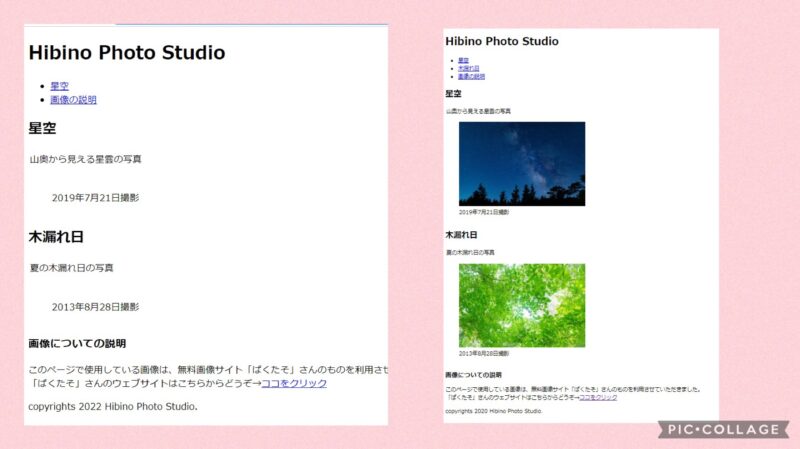
最初に作ったページと修正後の完成ページを見比べるとやっぱり達成感あります。(1回で出来ればなおよかったのですが。笑)
要素のこともきちんと知ることができたので、「今自分は何を書いてるのか?」をちゃんと理解しながら(一部のタグがまだあやふやだけど)HTMLを書くことができました。
次は、CSSを学ぶ!の回です。今回使ったテキストエディタを流用して文字の装飾をするみたいです。
実はCSSについては本を読んでもイメージがいまいちつかず…。自分で手を動かしながら理解できるよう頑張ってみます。
では、また!



コメント